Memory Types in GPU
One of the fascinating aspects of coding with CUDA is that we can freely choose which memory to use (meaning that when initializing a value or variable, we can specify it to be stored in a particular memory location) rather than letting the computer decide which memory to utilize. Thanks to this capability, we can fully leverage different memory types to optimize our program.
In this article, I will introduce the various types of memory within the GPU, along with the specific purposes of each. It’s important to note that this article is closely related to here. Therefore, if you haven’t read it yet, I recommend doing so before proceeding with this article.
Please note that in this article, I will focus purely on the theoretical aspects. The practical usage details will be covered in a subsequent article.
Before delving into the various memory types within a GPU, it’s important to understand that when we talk about memory, we generally categorize it into two main types: physical memory and logical memory.
Physical Memory: This refers to the actual hardware memory in a computer. It includes components such as RAM modules and storage devices like hard drives (HDD/SSD). Physical memory is where data and programs are stored directly and can be accessed quickly by the processor.
Logical Memory (Virtual Memory): This is the address space that the operating system and programs can access. Logical memory doesn’t necessarily have a direct one-to-one correspondence with physical memory. The operating system typically manages the mapping between logical addresses and physical addresses. This management helps allocate and manage memory for programs running on the system.
You can understand it in a simple way: when we code, we interact with logical memory, and once the code is finished, the data located in logical memory will be mapped to physical memory (meaning the computer will operate in physical memory).
Now that we have a foundational understanding of memory, let’s explore the specific memory types within a GPU and their purposes.
Logical view

As mentioned, Blocks and Threads are logical concepts, and due to the SIMT mechanism, it’s important to understand how Threads and Blocks are distributed and managed within the logical memory of the GPU.
Here, we have a familiar concept known as scope, which plays a crucial role in understanding how resources like Threads and Blocks are allocated and managed within the logical memory of the GPU.
- Local Memory: Each Thread can use its own local memory, where it can store temporary variables. This has the smallest scope and is dedicated to each individual Thread.
- Shared Memory: Threads within the same Block can share data through shared memory. This allows Threads within the same Block to communicate and access data faster compared to accessing global memory.
- Global Memory: This is the largest memory in the GPU and can be accessed by all Threads across all Blocks. However, accessing global memory is typically slower than other memory types, so optimization is necessary to avoid performance degradation.
- Texture Memory and Constant Memory: These are special memory types in the GPU optimized for accessing specific data types such as textures or constant values. All Threads across all Blocks can access these memory types
Physical view

It’s quite analogous to Blocks and Threads, but in this context, we’re talking about Streaming Multiprocessors (SMs) and Streaming Processors (SPs). Each SM possesses its own dedicated shared, cache, constant, and register memory. However, multiple SMs share the same global memory.
In this arrangement, SMs can manage their own local resources efficiently, such as shared memory for intra-block communication, and each SM’s processing elements (SPs) can work independently on their assigned tasks. The sharing of global memory allows for coordination and data exchange between different SMs, enabling them to work together on larger computational tasks.
Next, we will examine the data access speeds of these memory types.
Bandwidth of memory
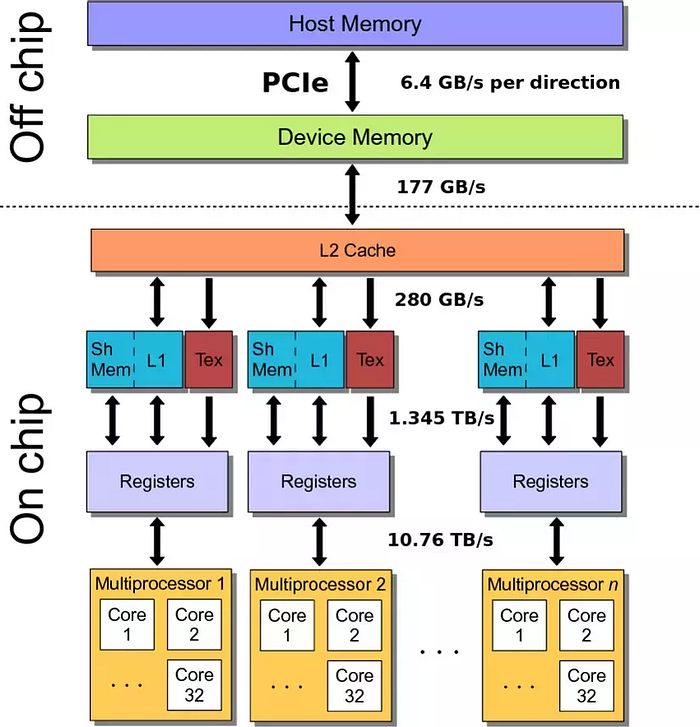
PCIe
As I mentioned before, the CPU (host) and GPU (device) are two separate components, each with its own memory, and direct access between them is not possible. Data must be copied back and forth through the PCIe (Peripheral Component Interconnect Express — bus), a commonly known interface.
One of the key factors in deciding whether to move data from the CPU to the GPU for computation is the PCIe, which, as shown in the diagram, has the slowest data transfer speed.
To address the challenge of copying a large amount of data from the CPU to the GPU, NVIDIA has introduced three methods:
- Unified memory
- Pinned memory
- Streaming ( hidden latency )
These methods will be discussed in more detail in upcoming articles.
Global memory
Global memory (also known as device memory) is the largest memory within the GPU and, due to its size, it has a relatively slower access speed, ranking just behind the PCIe in terms of access latency.
To overcome this challenge, in the upcoming article, I will introduce a parallel programming technique that helps improve the access speed of global memory. This technique is surprisingly simple and effective, and I will guide you through its implementation.
Global memory in the GPU is analogous to RAM in the CPU. When we initialize a value in the GPU without specifying its storage location, it is automatically stored in the global memory.
From this point, it’s evident that the primary purpose of global memory is to store large amounts of data.
Shared/Cache memory
Shared memory and cache are memory types with fast access speeds, but they have a smaller capacity compared to global memory.
Due to their high-speed nature, managing data in shared memory or cache can be more challenging than in global memory. One significant issue that heavily impacts access speed is called "bank conflict." We'll discuss bank conflict in more detail in upcoming articles.
Because shared and cache memory offer fast access speeds, we often use them to store data during computations. The typical approach involves first copying all the data from the CPU to the GPU and storing it in global memory. Then, we break down the data into smaller portions (chunks) and push them into shared memory for computation. Once the computation is complete, the results are pushed back to global memory.
Texture Memory và Constant Memory
As mentioned earlier, Texture Memory and Constant Memory are special memory types in the GPU optimized for accessing specific data types such as images (textures) or constant values. The access speed of these two memory types is quite fast, comparable to shared memory.
Therefore, the purpose of using Texture Memory and Constant Memory is to optimize data access and reduce the computation load on shared memory. Instead of pushing all the data into shared memory, we can allocate a portion of the data to Texture Memory and Constant Memory. This allocation strategy helps enhance memory performance by leveraging the optimized access capabilities of Texture Memory and Constant Memory.
A bit of interesting
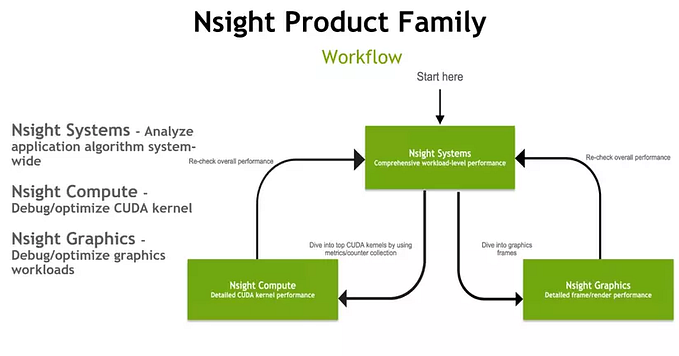
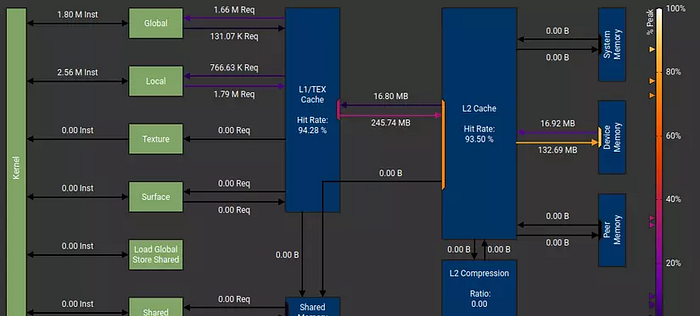
One small note is that the bandwidth values depicted in the diagram are illustrative, and for specific details about the bandwidth of each memory type on different devices, NVIDIA has developed two extremely useful and convenient tools for optimization and debugging: Nsight Systems and Nsight Compute. In the upcoming articles, I will explain how to use these two tools and their functionalities. Rest assured that even if your computer doesn’t have a GPU, you can still benefit from these tools. Here are some examples of how you can analyze your program using these tools:
Nsight system
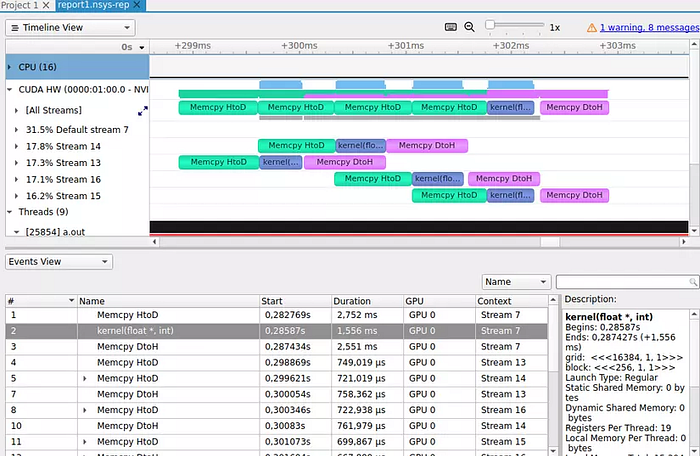
Nsight compute
References
Accelerating Radio Astronomy Cross-Correlation with Graphics Processing Units
HetSys Course: Lecture 4: GPU Memory Hierarchy (Spring 2023)
Parallel Implementations of ARIA on ARM Processors and Graphics Processing Unit