Pinned memory
In this article, I will discuss the concept of pinned memory — please note that it will be related to the next article (streaming), so it would be great if you could gain the knowledge in this article.
Before explaining what pinned memory is, I will go over how computers operate when we code for a clearer understanding — and rest assured, I will explain in a simple and easy-to-understand way, so it’s not necessary for you to have knowledge about hardware.
How computer work
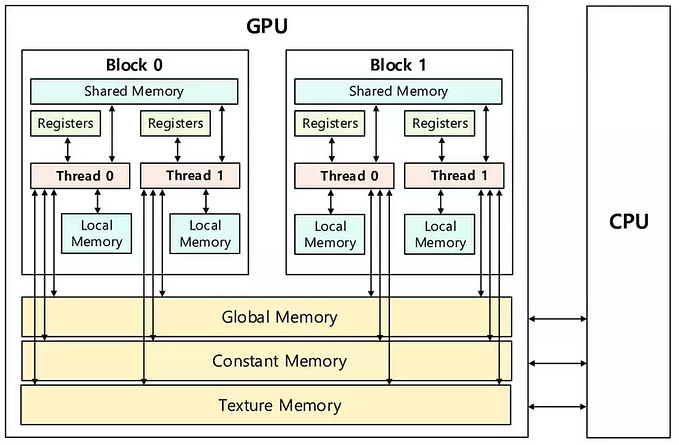
When it comes to memory, we always have two perspectives: Physical memory and virtual memory (or logical memory).
- Physical memory: the memory directly installed on the CPU and RAM sticks, connected directly. These are the memory cells located on the motherboard.
- Virtual memory: is an abstract concept (making it easier for programmers to manipulate), which is the memory managed by the operating system or drivers. The OS creates logical memory by using a part of the CPU’s space through mapping from logical to physical address in RAM.
The space of virtual memory is much larger than that of physical memory
Initially, when we allocate memory for the CPU, it is placed on RAM — Main memory (physical) or pageable memory (logical). Copying data from the CPU to the GPU when the data is on pageable memory can cause a significant problem known as swapping.
When data is stored in pageable memory, it might not always be ready for quick access because the system can move this data to the hard disk (magnetic disk) to free up RAM for other tasks. This process is called ‘swapping’.
When data needs to be transferred from the CPU to the GPU and that data is on the hard disk (due to swapping), you encounter a ‘missing data’ issue. This happens because the GPU requires quick access to the data, but the data is not readily available in RAM.
===> Therefore, CUDA has implemented a mechanism before copying from CPU to GPU to push all the data that needs to be copied to pinned memory (simply understood as pinning the necessary data so it cannot be moved down to the hard disk) and only after pushing everything to pinned memory does it start copying from the host to the device.
cudaMemcpy: means it will take 2 times copying (from pageable memory ==> pinned memory ==> device memory).
Instead of requiring 2 times copying, NVIDIA developed a function that allows us to specify from the beginning that data be stored in pinned memory (only taking 1 time copying from host to device).
Code
#include <cassert>
#include <iostream>
using std::cout;
using std::end;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockIdx.x * blockDim.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
void verify_result(int *a, int *b, int *c, int N)
{
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
}
int main()
{
constexpr int N = 100;
size_t bytes = sizeof(int) * N;
// Vectors for holding the host-side (CPU-side) data
int *h_a, *h_b, *h_c;
// Allocate pinned memory
cudaMallocHost(&h_a, bytes);
cudaMallocHost(&h_b, bytes);
cudaMallocHost(&h_c, bytes);
for (int i = 0; i < N; i++)
{
h_a[i] = rand() % 100;
h_b[i] = rand() % 100;
}
// Allocate memory on the device
int *d_a, *d_b, *d_c;
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
// Copy data from the host to the device (CPU -> GPU)
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice);
int NUM_THREADS = 1 << 10;
int NUM_BLOCKS = (N + NUM_THREADS - 1) / NUM_THREADS;
// Execute the kernel
vectorAdd<<<NUM_BLOCKS, NUM_THREADS>>>(d_a, d_b, d_c, N);
// Copy data from device to host (GPU -> CPU)
cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost);
// Check result for errors
verify_result(h_a, h_b, h_c, N);
// Free pinned memory
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
// Free memory on device
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cout << "COMPLETED SUCCESSFULLY\n";
return 0;
}It simply differs in that the allocation of data for the host is done using cudaMallocHost.
Exercise
Write a script to compare the time taken to copy data from H2D — D2H between pageable memory and pinned memory
The solution is here