Terminology in parallel programming
In this article, I will explain some commonly mentioned terms in parallel programming
PHYSICAL and LOGICAL
Before explaining the concepts of “PHYSICAL” and “LOGICAL,” let’s go through an example to provide a general and easy-to-understand overview.
Example: A school has multiple classrooms, and each classroom contains several students (the number of classrooms and students per classroom varies depending on different schools, considering various factors, but money is one of the most important). Next, we have a mountain of tasks (the number of tasks is unknown — I will explain this clearly in the following section) that needs to be distributed among the students for processing, and we must adhere to the following RULES:
- Each classroom can handle a maximum of 1024 tasks.
- At any given time, within a classroom, (32 * the number of warps) tasks will be executed (I will explain what a warp is in the following section, and the number of warps will depend on the computer architecture). Therefore, if we have 5 classrooms, there will be (32 * the number of warps * 5) tasks executed. For N classrooms, there will be (32 * the number of warps * N) tasks executed.
To summarize, “PHYSICAL” can be understood that being observable, have a fixed quantity, and in this example, it refers to the students. On the other hand, “LOGICAL” refers to that cannot be directly observed but can be imagined or conceptualized, with an unspecified quantity. In this case, it represents the tasks.
Physical corresponds to SM and SP

In the given picture, we can see that there are 16 SMs, and each SM contains 32 cores. So, what are SM and cores?
Streaming Processors(SPs or cores). The SPs are the main processing units on the GPU and are capable of executing computations concurrently on multiple data elements. You can think of SPs as individual students (1 student being 1 SP). The more SPs (students) we have, the greater the number of tasks that can be processed concurrently.
Streaming Multiprocessor(SM or multiprocessor ) is a collection or grouping of SPs. It can be understood as a class or classroom that accommodates multiple SPs. The SM acts as a higher-level unit that manages and coordinates the execution of tasks across the SPs within it.
The number of SMs and SPs may vary depending on the specific GPU architecture of each computer, and the count is typically fixed for a given GPU model.


Logical corresponds to thread, block and grid

In the given picture, we can see that there are 6 Blocks, and each Block contains 12 threads. So, what are Blocks and Thread?
In simple terms:
Thread can be understood as a unit of work, where each thread represents an individual task or job to be executed. So, one thread corresponds to one task.
Block refers to a collection or group of threads. It represents a batch or a set of related tasks that are executed together. However, there is a maximum limit on the number of threads in a block, which is typically 1024 threads. This limitation is imposed by the computer’s architecture and applies to most GPUs.
To summarize, a thread represents a single task or job, while a block is a grouping of threads that collectively perform a set of related tasks.

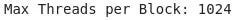
Grid refers to a collection or set of blocks. It represents a higher-level grouping that encompasses multiple blocks. Each block consists of multiple threads, and multiple blocks together form a grid.
It is important to focus on understanding threads and blocks, as they are fundamental units of parallel execution.
In this context, “tasks” refer to data. In each problem or task, we will have a different quantity of data to process. This is why I mentioned that the number of tasks is unspecified or unknown in advance, as it can vary depending on the specific problem or scenario.
The numbers (0,0) and (0,1) serve as indices to determine the position of a block and a thread, similar to a matrix. For example, a[1][2]. However, the indexing mechanism here has a slight difference, which I will explain in more detail in subsequent discussions.
You might wonder why we divide the threads into separate blocks instead of having one large block for simplicity. If we did that, we would violate RULE 1, which states that each classroom can handle a maximum of 1024 tasks. Hence, we need to divide the threads (i.e., the number of tasks) into smaller blocks.
One significant advantage of dividing threads into blocks is related to RULE 2: if we have 1024 threads, we only need one block. However, at any given time, it can only process (32 * 1) tasks (assuming the number of warps is 1). Thus, we have to wait for it to finish processing the first 32 tasks before moving on to the next 32 tasks, and this process continues sequentially.
If we divide the threads into 32 blocks, with each block containing 32 threads (32 * 32 = 1024), then at any given time, it can process all 1024 threads without waiting for sequential execution.
It is similar to the analogy of eating cakes, where instead of sequentially processing 32 cakes (threads) at a time, we can process all 1024 cakes (threads) in parallel.
Summary:
SM(s) are the classrooms, 1 SP is a student, 1 Thread is a task, and Block is a collection of tasks. You can imagine a block as a box containing the tasks that need to be processed. Each SM processes a certain number of blocks (depending on the data distribution) — 1 SP can handle more than 1 thread (1 student can perform multiple tasks).
Now, we encounter the question of how to distribute the tasks (blocks) among the classrooms (SMs) since SMs and Blocks are two separate concepts (physical and logical) that cannot directly interact. We need an intermediary called WARP to handle this distribution. So, what is a warp, and what is the significance of the number 32?
WARP: both physical and logical
A warp refers to a group of threads that are executed together in parallel. In most GPU architectures, a warp typically consists of 32 threads. The GPU processes instructions in a SIMD (Single Instruction, Multiple Data) fashion, where a single instruction is executed on multiple data elements simultaneously within a warp. This means that all 32 threads within a warp execute the same instruction but operate on different data.
The number 32 is significant because it represents the size of a warp in most GPU architectures. It determines how many threads are processed together in a parallel execution unit. By having multiple warps executing in parallel, the GPU can achieve high throughput and efficient utilization of its processing resources.
Returning to the school example, the warp represents the leaders or class monitors (the number of warps or leaders depends on the specific computer architecture, such as Tesla, Fermi, etc., which I will explain in a separate discussion). The leaders (warps) have two tasks:
- They go and fetch the blocks to bring back to their group for processing. In this case, the blocks are already assigned to each classroom (SM).
- After bringing the blocks to their group, the warps distribute the blocks among the individual students for processing. The warp handles the second step, while the first step will be explained in a subsequent discussion.
Once the warp brings the blocks to their group, they also have the additional responsibility of dividing the tasks among the members within the group. Each division can handle a maximum of 32 tasks at a time. After the completion of these 32 tasks, the next set of 32 tasks is distributed. In other words, at any given time, a warp distributes 32 threads, and each classroom can have multiple warps (leaders), resulting in the number of tasks at a given time being (32 * the number of warps) tasks.
The reason why a warp can only distribute a maximum of 32 threads is due to the functionality of the computer architecture, which is applicable across different systems.
To summarize:
- Warp (Physical): Represents the leaders who lead the students in their group. In other words, warps control the SPs in task processing, where each SP is assigned a specific task.
- Warp (Logical): Represents the control over the number of threads (tasks).
One important note is that while we use the analogy of warps as group leaders, they are not counted as individual members within the classroom. For example, if a classroom has 50 students and 5 leaders, the number of SPs (students) is still 50, not 55.
