Unified memory
In this article, I will introduce Unified memory — it can be said that Unified memory was a major breakthrough during the Cuda 6.0 era.
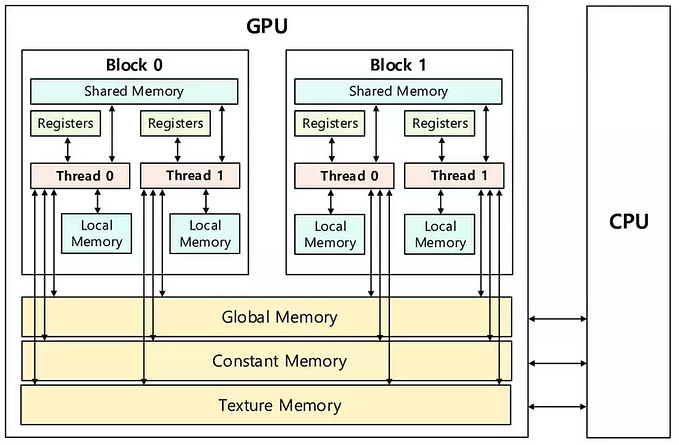
Unified Memory is a special type of memory (located on the CPU) that can be directly accessed by both the CPU and GPU without the need to copy data back and forth between two separate memory types.
This is why Unified Memory is called based on the zero-copy principle.
As I have mentioned, when talking about memory, there are always two concepts: Physical memory and Virtual memory. Unified memory has different perspectives in these two concepts:
- Virtual memory (developer view): From this perspective, Unified Memory is a unified memory between CPU and GPU (where both CPU and GPU can directly access it).
- Physical memory (computer view): As I have mentioned, the CPU and GPU have separate memories and cannot directly access each other (only through PCI). Here, Unified Memory is located on the CPU, but thanks to the zero-copy mechanism, we perceive Unified Memory as a unified memory of CPU and GPU.
Zero Copy: This is a data transfer optimization method, where data is AUTOMATICALLY transferred directly from the memory of one device (e.g., CPU) to another device (e.g., GPU) without going through an intermediate step (like a buffer). This significantly reduces the time and resources needed for data copying, thereby improving performance.
Summary
Unified Memory is a special type of memory that, when used, eliminates the need for us to worry about the process of copying from host to device (h2d) or device to host (d2h), as these tasks are handled automatically by the computer. This makes memory management easier for us. However, due to its automatic nature, it is not optimized and can lead to issues known as page faults.
Page faults
Page faults occur when the CPU or GPU requests access to certain data in its memory, but that data has not yet been loaded from Unified Memory.
In simple terms, Unified Memory can be understood as an intermediary memory between the CPU and GPU. When there’s a data change in Unified Memory, this change is simultaneously reflected in both CPU and GPU (based on a mapping mechanism). However, we cannot predict when this data will be mapped back to the CPU and GPU, leading to page faults (the requested data is not found).
When a page fault occurs, the computer implements the Memory Management Unit (MMU) mechanism: the device sends a page fault request to the MMU to check whether the data exists or not, and if it does, it will be loaded.
Thus, each time a page fault occurs, a significant amount of time is consumed for the MMU to locate the data.
It’s important to note that page faults only occur when using the zero-copy mechanism in general and Unified Memory in particular. Conventional methods like cudaMemcpy do not experience page faults because, in these cases, we specify that data should be completely copied before processing, similar to following a step-by-step sequence.
Code
#include <stdio.h>
#include <cassert>
#include <iostream>
using std::cout;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
const int N = 1 << 16;
size_t bytes = N * sizeof(int);
int *a, *b, *c;
cudaMallocManaged(&a, bytes);
cudaMallocManaged(&b, bytes);
cudaMallocManaged(&c, bytes);
for (int i = 0; i < N; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
}
int BLOCK_SIZE = 1 << 10;
int GRID_SIZE = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<GRID_SIZE, BLOCK_SIZE>>>(a, b, c, N);
cudaDeviceSynchronize();
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
cudaFree(a);
cudaFree(b);
cudaFree(c);
cout << "COMPLETED SUCCESSFULLY!\n";
return 0;
}This is a simple code example for adding two vectors using Unified Memory. As you can see, the process of copying from host to device (h2d) and device to host (d2h) has been omitted. Instead, the integers a, b, c are stored in Unified Memory using cudaMallocManaged. As mentioned earlier, we need cudaDeviceSynchronize() to synchronize the CPU and GPU after the zero-copy process. However, this code will experience page faults.
To check for and address page faults, you can follow these steps:
$nvcc .cu
$./a.out
$nsys nvprof ./a.out (Please note that to run this command, you need to have Nsight Systems installed. I have written a guide on how to install it in a separate article.)
It’s clear that in the profiling output, there are 18 instances of device-to-host (d2h) copies and 46 instances of host-to-device (h2d) copies, which is a significant number. This indicates that page faults have occurred due to the zero-copy mechanism used in Unified Memory.
Fix
#include <stdio.h>
#include <cassert>
#include <iostream>
using std::cout;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
const int N = 1 << 16;
size_t bytes = N * sizeof(int);
int *a, *b, *c;
cudaMallocManaged(&a, bytes);
cudaMallocManaged(&b, bytes);
cudaMallocManaged(&c, bytes);
// Get the device ID for prefetching calls
int id = cudaGetDevice(&id);
// Set some hints about the data and do some prefetching
cudaMemAdvise(a, bytes, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId);
cudaMemAdvise(b, bytes, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId);
cudaMemPrefetchAsync(c, bytes, id);
// Initialize vectors
for (int i = 0; i < N; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
}
// Pre-fetch 'a' and 'b' arrays to the specified device (GPU)
cudaMemAdvise(a, bytes, cudaMemAdviseSetReadMostly, id);
cudaMemAdvise(b, bytes, cudaMemAdviseSetReadMostly, id);
cudaMemPrefetchAsync(a, bytes, id);
cudaMemPrefetchAsync(b, bytes, id);
int BLOCK_SIZE = 1 << 10;
int GRID_SIZE = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<GRID_SIZE, BLOCK_SIZE>>>(a, b, c, N);
cudaDeviceSynchronize();
// Prefetch to the host (CPU)
cudaMemPrefetchAsync(a, bytes, cudaCpuDeviceId);
cudaMemPrefetchAsync(b, bytes, cudaCpuDeviceId);
cudaMemPrefetchAsync(c, bytes, cudaCpuDeviceId);
// Verify the result on the CPU
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
// Free unified memory (same as memory allocated with cudaMalloc)
cudaFree(a);
cudaFree(b);
cudaFree(c);
cout << "COMPLETED SUCCESSFULLY!\n";
return 0;
}run again to see the result
Explain
some special functions that can be used to optimize memory management in CUDA, particularly when using Unified Memory. These functions include:
cudaMemAdvise: This function provides hints on how to manage memory on the CPU or GPU. The hints offered by cudaMemAdvise include:
- cudaMemAdviseSetReadMostly: Suggests that the memory region will be read frequently.
- cudaMemAdviseUnsetReadMostly: Indicates that the previous read-mostly advice no longer applies.
- cudaMemAdviseSetPreferredLocation: Suggests that the memory region should be located on a specific GPU device.
- cudaMemAdviseUnsetPreferredLocation: Indicates that the previous preferred location advice no longer applies.
- cudaMemAdviseSetAccessedBy: Suggests that the memory region will be accessed by one or more GPU devices.
- cudaMemAdviseUnsetAccessedBy: Indicates that the previous accessed-by advice no longer applies.
cudaMemPrefetchAsync: This function is used to prefetch data from a memory region on the host or device to another region on the device or host. It allows explicit control of the data prefetching process to optimize performance and efficient data access on the GPU.
Exercise
write a simple code to demonstrate Unified memory can be accessed by both GPU and CPU
the solution is here

![[vLLM — Prefix KV Caching] vLLM’s Automatic Prefix Caching vs ChunkAttention](https://miro.medium.com/v2/resize:fit:679/0*9Fsj4uI4JdMwptGY.png)

